How to Actually Influence AI Answers
Topic: Clearscope
Published:
Written by: Clearscope
There is a great deal of discussion about how to “optimize for AI.” Most of it assumes that influence happens inside the model itself, and that if you publish enough content, refine enough language, or repeat a concept often enough, the model will somehow absorb it directly into its memory.
That is not how influence works.
You can't edit a model’s internal training data. You can't alter its stored representations. And you can't directly modify what it already “knows.” Those systems are fixed once trained, aside from formal updates controlled by the model provider.
But that does not mean AI answers are immune to influence. It simply means influence happens somewhere else.
The key distinction is this: many models do not rely exclusively on internal memory when generating responses.

They retrieve. In other words, search.
Before producing an answer, they often perform web searches, translate prompts into underlying query structures, gather content, and synthesize from what they find. That retrieval layer is dynamic. It interacts with the live web. And unlike internal model weights, it is competitive.
Influence does not occur inside the model’s training data. It occurs at the moment of retrieval.
Retrieval Is the Influence Surface
When a model runs web searches before answering, it is not consulting a hidden AI-only index. It is pulling from traditional search results — the same indexed pages that appear in conventional SERPs.
Those results are not static. They are shaped by relevance, structure, authority, and coverage. They are subject to ranking mechanics. They are, in practical terms, impressionable.
If a model retrieves documents before generating a response, then influence depends on whether your content is present within the set of documents it considers.
This shifts the strategic question.
Instead of asking, “How do we train the model to remember us?” the more productive question becomes, “How do we ensure we are consistently retrievable when the model searches the web?”
Study the Searches, Not Just the Answers
Most analysis of AI focuses on outputs. People examine the final response and try to reverse-engineer why a brand appeared or did not appear. That approach is incomplete.
The answer is assembled from underlying web searches. A single user prompt may trigger multiple web queries. Each query may explore a slightly different framing of the question. The final response reflects what surfaces across those retrieval events.
When you sample responses at scale, patterns become visible. The same query structures recur. The same clusters of domains resurface. The same brands appear repeatedly within specific topical categories.
The search space is not infinite. It is bounded.
Large-scale sampling reveals what could be called the recurring retrieval set — the group of queries, sources, and themes the model consistently draws from when constructing answers. Once that structure is visible, influence becomes less mysterious. You are no longer guessing at isolated answers; you are observing the model’s underlying behavior.
Influence Means Entering the Candidate Set
The goal is not to control the model. It is to enter the candidate set it selects from when it retrieves information. In other words, the group of pages that appear in the SERPs it pulls from.
When a model performs a search, it assembles a pool of possible documents. From that pool, it synthesizes an answer. If your content is not in that pool, it cannot meaningfully shape the output.
Influence, then, depends on retrievability.
Retrievability requires:
Alignment with the query patterns the model generates
Comprehensive coverage of the topic so that multiple query variations can surface the same document
Structural clarity and authority sufficient to compete within conventional search results
This is not about exploiting loopholes. It is about being consistently present in the moments where the model recalculates what is relevant.
Over time, repeated inclusion matters. Documents that surface frequently across retrieval events exert more structural influence than those that appear once.
Sampling Reveals Relative Weight
When retrieval patterns are analyzed across large volumes of responses, frequency begins to suggest importance.
If certain web search queries appear repeatedly across prompts, they likely carry more weight in shaping outputs. If certain domains surface across diverse prompt types, they likely occupy structurally important positions within the retrieval landscape.
This does not mean every search event is equal. Some queries appear consistently and form the backbone of answer construction. Others are more peripheral.
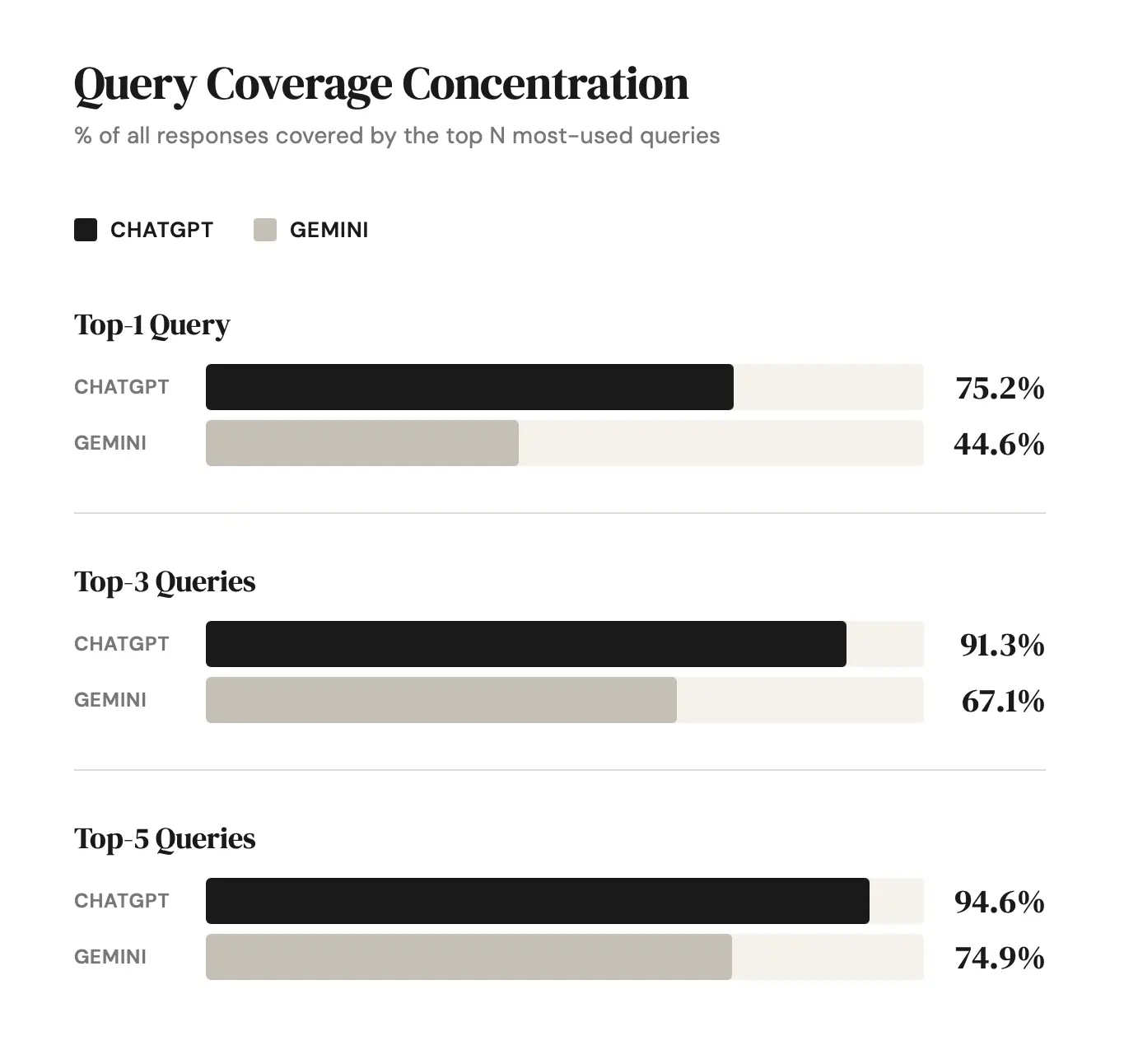
At scale, analysis can reveal:
Which query structures recur most frequently
Which domains consistently surface across varied prompt types
Which topics show concentrated competition
Where gaps exist within the recurring retrieval set
By ranking query frequency and domain recurrence, it becomes possible to identify where influence is most concentrated — and where opportunity exists to enter that structure.
How to Actually Influence AI Answers
If influence occurs at retrieval (as in, influence doesn’t happen inside the model’s memory and it doesn’t happen during training) then the process becomes much clearer.
Step 1: Identify the model’s retrieval behavior
Determine whether the system searches frequently or selectively. Influence is more dynamic in search-first systems and slower in recall-heavy systems.
Step 2: Analyze the model’s recurring query patterns
Sample responses at scale and observe the searches triggered before answers. Look for recurring query structures and thematic clusters. These patterns reveal how the model translates prompts into searches and where influence actually enters.
As you analyze those high-frequency queries, note which domains consistently surface within them. Those sources represent the current competitive landscape inside the model’s retrieval layer.
Step 3: Align content with high-frequency query structures
Create or refine content that directly matches the types of searches the model repeatedly runs.
Step 4: Strengthen retrievability, not memorability
Focus on indexability, topical depth, and authority within conventional search systems. Influence depends on being selected at retrieval time.
Step 5: Monitor recurrence over time
Influence compounds through repeated inclusion. Track whether your domain begins to appear consistently across varied prompts.
These steps apply most directly to models that retrieve from the live web before answering, where influence is visible at the moment of search.
The Practical Shift
The practical shift is straightforward.
You cannot change what the model has already memorized. But you can compete in the environment it consults when it seeks additional information.
Influence is not about embedding yourself in the model’s internal weights. It is about ensuring that when the model searches, your content is part of the recurring set it considers.
AI answers are not entirely fixed, nor are they entirely fluid. They are shaped by retrieval behavior.
If you understand that behavior, influence becomes less about speculation and more about structured participation in the candidate set.
That is how AI answers are actually influenced.
Bad News: It's Not Just Listicles
January traffic declines aren’t format-specific. We break down how Gemini 3 and AI Overviews are reshaping organic visibility.
11 takeaways From Clearscope’s Roundtable on the Future of Search in 2026
Key takeaways from Clearscope’s AI search roundtable with Lily Ray, Kevin Indig, Ross Hudgens, and Steve Toth on SEO, AEO, and what matters in 2026.
Your Organic Traffic Is Not Coming Back (The Sky Is Falling—and That’s Okay)
The search era has shifted from retrieval to generation. Organic traffic won’t return, but brand visibility is expanding across AI systems. Here’s how to adapt.